
Organización de Proyectos
Este va a ser un breve post sobre cómo organizar los proyectos que hagan en R. Es al día de hoy la que utilizo y si googlean van a ver que existe y es usada en el ámbito. Puede ser esta tal cual o alguna alternativa similar.
El enfoque es muy sencillo e intuitivo. La idea es tener por separado cada componente del proyecto y de manera clara y segmentada para poder acceder rápidamente a lo necesario, ya sea código, datos, outputs, etc.
Primero y principal. CREEN UN PROYECTO en R. Esto va a facilitar todo el manejo de rutas, llamados a otros códigos y mismo para compartir si es necesario con otra gente ya que las rutas que utilicemos serán relativas a la ubicación en Disco del proyecto. Por lo tanto si el proyecto está creado en C:\ProyectoR y en algún codigo llamamos a read.csv("/Datos/datos.csv") esto funcionará en cualquier computadora donde el proyecto tenga en su directorio una carpeta “Datos”, independientemente de la ruta donde se encuentre. Yo puedo mover toda la carpeta del proyecto a C:\OtraRuta y ejecutar ahí el read.csv sin tener que actualizar la ruta. Es uno de los problemas más básicos y molestos al trabajar con códigos ajenos o mover nuestros proyectos de lugar.
Carpetas
Una vez creado el proyecto, lo que sugerimos es crear una estructura de carpetas como la que se ve en la imagen siguiente.
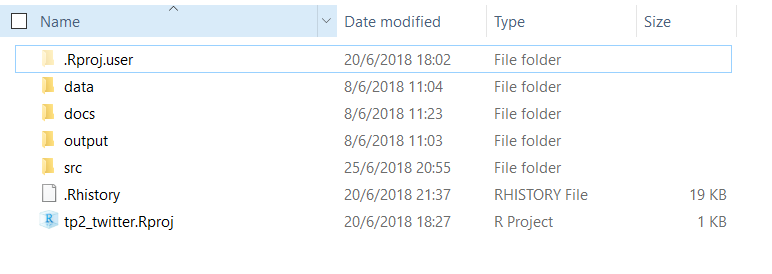
DATA
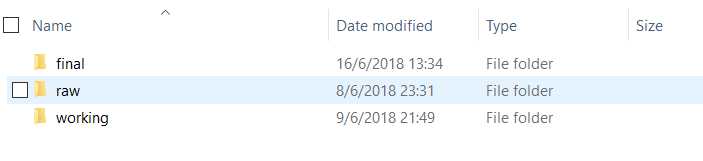
Contiene la data que será el input de nuestros proyecto. A su vez podemos guardar archivos intermedios que hayamos ido procesando. Pueden adaptarlo como prefieran pero sugerimos guardar en “raw”,la data que será input del análisis, ya sean csvs, txts, htmls, etc.
En “working”" ir guardando objetos importantes o que lleven tiempo de procesar asi se pueden leer directamente en vez de tener que correr el código nuevamente en una próxima sesión.
Para ellos se usa el comando saveRDS().
En “final” guardar los objetos finales del análisis.
DOCS
Acá guardamos archivos auxiliares útiles como diccionarios de variables, links a webs, consignas, documentación, etc.
OUTPUT
Acá exportamos los resultados del análisis, desde gráficos que vayamos a usar en el reporte, el informe final que hagamos (PDF, HTML,etc), las conclusiones que saquemos, etc. Dependiendo de la complejidad del proyecto puede separar en carpetas al interior si hay outputs muy variados.
SRC
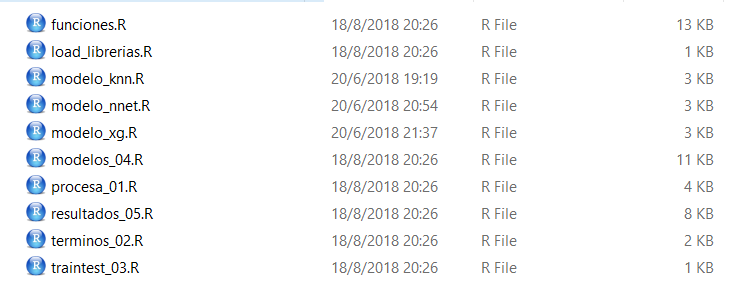
Carpeta para todo nuestro código. Algunos eligen no usarla y dejar los códigos en la ruta del proyecto pero me parece un poco desprolijo.
Recomendamos tener muchos scripts con títulos claros y segmentados por lo que hacen. Es decir, uno para levantar la data, otro para análisis exploratorio, otro para feature engineering y así. A su vez, recomendamos tener un script propio para la funciones que definan ustedes y si les resulta cómodo otro para las librerías, de manera tal de tener todo claro, separado y no tener que andar buscando dentro de un grán código lo que necesitan. Además es más sencillo para modificar y arreglar bugs. Recuerden que para invocar código de otro script simplemente lo corren usando source("Script.R").
Dejamos un ejemplo ilustrativo.
GITHUB
En algún otro post lo dijimos pero recomendamos altamente UTILIZAR GITHUB para manejar sus proyectos, tener backups, compartirlos y actualizarlos desde cualquier computadora! Y hacer blogs como este siguiendo este POST
Lo que también sugerimos es no subir la carpeta data a github por dos motivos. Primero por una cuestión de espacio, si tienen data muy pesada Github no les va a permitir incluirla en el repositorio. Por otra parte si la data es confidencial o tiene datos privados mejor que no esté a disposición de cualquiera si tienen cuenta pública. Obviamente queda a criterio y comodidad de cada uno si corresponde subir la data o no. Para evitar que una carpeta sea subida a github solo deben incluirla en el archivo .gitignore de su repositorio.
